
Dear software people,
Unicode is older now than ASCII was when Unicode was introduced. It’s not a weird new fad.
It’s complicated but so is the domain it represents. We recognize that we have to think about time zones and leap days and seconds, for instance. And it’s a cleaner abstraction when you aren’t halfhearted about it.
Sincerely,
Charlie
@isagalaev It’s a technically solved problem if you make the effort to use the solutions. Some don’t. They assume that a character is a byte, or they consider systems that mishandle Unicode to be good enough to keep in service. That’s the halfheartedness I mean. It may not be specific to Unicode but it’s real.
(Analogously, you still see bugs from daylight saving time shifts, integer overflows, SQL injection, and other problems that are totally solved if you bother to use the solutions.)

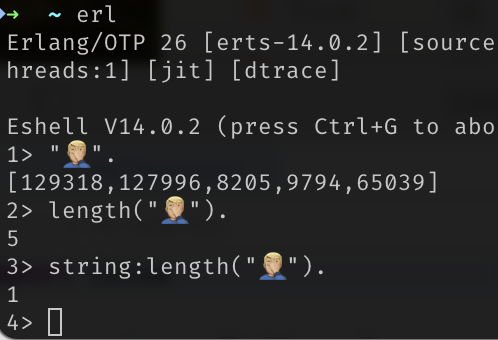
@isagalaev @vruba not by default, no. What’s "🤦🏼♂️".length in your language of choice?

@nikitonsky @isagalaev @vruba "🤦🏼♂️".length – I find it hard to fault Unicode for this.
IMO this has a lot more to do with programming languages that enable humans to trust their intuition when they really shouldn't.

@eiggen
I suspect Niki would agree that it's not Unicode that's the problem here, but the defaults for how strings are handled in various languages. "😰".length is also kind of … what information are you looking for? The space it takes on disk or wire, or what a human would consider visible characters, or something else entirely? Or: What unit of measurement should the answer have?

@eiggen @isagalaev @nikitonsky @syklemil @vruba already in a low-level C library I carry three different kinds of lengths: the size: amount of bytes (UTF-8 coded), count: amount of multibyte/wide characters, width: amount of fixed-width screen cells this uses (2).
It gets worse when you throw grapheme clusters into the mix, which so far I’ve left to higher-level code but will have to look at eventually as well…

@nikitonsky @isagalaev @vruba Swift is the only language I’ve worked in that handles this correctly over a wide range of issues. It’s also why its String type infuriates so many when they first come to Swift. myString[2] isn’t possible in Swift; there’s no O(1) way to get “the nth Character.” When you finally accept that this a key consequence of any deeply Unicode-aware language, it’s a big change in how you think about strings.
To your question: in Swift, that returns 1 (using .count).
@cocoaphony @isagalaev @vruba I’ve heard that Erlang is the second one, but that’s about it. Shame, really
@nikitonsky @isagalaev @vruba Erlang *can* do it, but only if you explicitly ask for it. The normal "string" type in Erlang is a charlist, which is just a list of Unicode scalars. Swift is the only language I know whose most-used string type is defined as a sequence of grapheme clusters, and whose normal operations are on those clusters.
For example, appending a combining character does not increase the length of Swift String. It's correct, but very unusual and a little surprising.
@nikitonsky @isagalaev @vruba If this stuff interests you, one of my favorite talks I've given was on just this subject. https://www.youtube.com/watch?v=Cz64DHcRxAU

@cocoaphony @nikitonsky @isagalaev @vruba
Delphi use utf8 if you want. But there are problems with other Editors. BOM or not BOM
https://blogs.embarcadero.com/the-delphi-compiler-and-utf-8-encoded-source-code-files-with-no-bom/


@nikitonsky @vruba okay, okay, admittedly I meant it in a very narrow sense of "everyone thankfully uses utf-8 everywhere by now", so text data is interoperable. I didn't mean all the interesting cases are solved.
Like the length of that emoji, where the correct answer is "emojis don't have a well defined meaning of length", so nobody should assume anything in this case. But as it turn out, mostly people care about the count of utf-8-encoded bytes, for storage or memory allocation.
@isagalaev @nikitonsky At a systems programming level, people certainly care more about storage size. But at a UI level, they might want to ensure that only one emoji can be used in a certain context. So perhaps it’s better to say that there are multiple useful senses of the idea of “length” that might matter in different areas. But I think we basically agree about the important parts of this issue.
@vruba @nikitonsky but the part about "only one emoji can be used in a certain context" is interesting. What context? Emoji pickers in UI couldn't care less about `.length`, they are tables of grapheme clusters, where each emoji is a full utf-8 encoded string that gets appended to a string in a text input. Nobody cares if its length is 1 or more.
It's just not a(n important) use case. Just like it turned out that nobody needs random access to "characters" in a string by index in O(1).
@isagalaev @nikitonsky Think of emoji reactions or status fields. They could be implemented in such a way that it is reasonable to check that the user only submits one emoji at a time, or at least that only one is displayed at a time. Or consider CSS use cases like https://developer.mozilla.org/en-US/docs/Web/CSS/::first-letter
@isagalaev @nikitonsky All I’m saying is that the length of a string as a reader would understand it (not only as a hard drive would understand it) is a useful concept that should be exposed by at least some string libraries. I strongly agree with you that it’s not worth optimizing for at the cost of, well, almost any other operation.
@vruba @isagalaev Even simpler. Doing this is impossible without being aware of grapheme clusters
@nikitonsky @vruba as for the contraction with "…", UIs seem to universally converge on visual hiding with a transparency gradient, because the visual width of a string only makes sense after being rendered with a particular font on a particular device. Doing `str[:max] + '...'` was only good enough in the beginning.
@isagalaev @vruba remember when every cyrillic letter was counted as two for character limit at Twitter? Those were not the fun times
@isagalaev @vruba I disagree. Emoji length is well-defined (in the same Unicode standard that you are so happy everyone uses). Even more, that definition _is consistent_ with what people expect it to be.
The problem is that most programming languages _choose to ignore_ that and instead give you a metric that has no practical use whatsoever (unicode codepoints)
@nikitonsky @vruba ah, that's a good clarification, thanks! I didn't know it was defined. Although I believe the story with languages not supporting it is more complicated than just choosing to ignore.
I'm going to still consider unicode a solved problem, even if it means "except emoji". It's just so much better now than it was ~20 years ago.
@isagalaev @vruba I specifically address this misconception about “only emoji”, see “Is Unicode hard only because of emojis?” in https://tonsky.me/blog/unicode/

@isagalaev @nikitonsky @vruba "everyone uses utf8 everywhere now" -- coders still using raw Win32 API and/or Java look on and lolsob in UTF16

@nikitonsky @isagalaev @vruba .Length is 7 in dotnet; we need System.Globalization.StringInfo("🤦🏼♂️").LengthInTextElements to get 1 grapheme.

> Nobody writes new software that's not unicode-aware
This is just categorically false. It happens all the time in new software. Frequently some parts of the system will accept Unicode but many little corners either won't take it or mangle it or whatever.

@isagalaev @vruba It's not just old software, it's also old standards. I recently stumbled over this QR decoding issue, it's depressing. You can specify the codec in the QR code, but many people don't. The standard says it's ISO-8859-1 in this case, but more likely it will be either BIG-5 or UTF8 and the decoder has to guess. (If it wants to guess correctly, it should check probabilities with a language model or something...) https://github.com/mchehab/zbar/issues/212

It's way more messy for CJK due to Han unification: given that you actually want to draw the "same" pictogram differently across different languages, you need to pick a font depending on the language. :(
@isagalaev @vruba haha I wish…

@isagalaev @vruba you would be surprised what (new) software I come across every once in a while


@vruba Dear Microsoft,
UCS-2, and thus UTF-16, were a wrong-headed mistake from the start. Join the rest of us over in UTF-8 land, and stop trying to ice-skate uphill.
@spacehobo @vruba UCS-2 was entirely reasonable at the beginning, when Unicode (pre 10646) was a 16-bit encoding.
Before Plan 9’s UTF-8, no other encoding was really suitable for all use cases.
@mirabilos @vruba Cool, and when did Windows choose UTF-16? Was it before or after Plan-9 invented UTF-8?
@vruba @spacehobo after, but at that point they had ab ABI and everyone will inform you ABI breakage is bad (except OpenBSD who’ll just recompile everything).
You’ll be glad to now they managed to make UTF-8 fit into the codepage system as cp65001 many years ago, and nowadays there’s also a global-ish all-text-is-UTF-8 toggle. Doesn’t affect the wide APIs much, but they now recommend using the *A APIs with UTF-8 so your application can operate on them or UCS-4 at libitum (and encode the UCS-4 to UTF-8 for calls like on Unix).

@vruba And you finally can have slashes in your filenames. Thanks, UTF! 👏

@vruba I love unicode but whyyyy are the specs still released canonically as XML?



@vruba Amen. For obvious reasons.
@vruba unfortunately, most people don’t do for leap seconds. Ask me how I know…

@vruba It solves the encoding problem but It's frighteningly unusable from the data entry side. Granted, that's not the problem it was designed to solve but it's frustrating having the possibility of writing (say) technical text with proper characters lost in a sea of characters not used in the text. We went from slightly less than 128 usable characters to a near infinite amount of noise (nobody uses but a tiny fraction of what the encoding makes available). The encoding is fine but it's a pity editors and other software haven't caught up to the representation.

@vruba I have bad news about how well software engineers reason about time zones


@vruba Han unification (and related Syriac and Nastaliq issues) aren't well solved issues. But plain ASCII doesn't help you there!
@pnorman Right – the point is not that Unicode is perfect, because it has various obvious warts and arguable major design flaws. It’s that its utility vastly exceeds any realistic alternative’s, especially ASCII’s, for basically all user-facing software.
@pnorman Someday that will change, and that will be a new question. For now, as I expect you agree, arguing for ASCII as the only way to do strings is like arguing for 32-bit unsigned integers as the only way to do numbers. “But they’re fast and easy to reason about!”

@vruba i never thought about that, but you're right lol

@vruba Dear software people : *DO NOT* dare to use UNICODE in Windows / VS or such, there's NO such "standard" as "the standard". Just use UTF-8 encoding for it and be sure NOWHERE in your code there's WCHAR and/or wchar_t ! .. otherwise NOTHING will EVER work the way it SHOULD. You may end up with "WCHAR" at 32 bits still encoded in UTF-8 ( i.e. instead of bytes8 using long32 but still with UTF-8 encoding ). Also beware of BOM and such and compiler options. It's a PROPER MESS ! ( CONT ).
@vruba ( CONT ) also NOT even L"string" will guarantee you that string is really UNICODE ( 16 ? 32 ? ) I've seen all sort of unbelievable things happening. Beware also at exchanging "files with translations" between people .. already just saving a ".txt" or ".csv" file may cause lot of problems. Beware of those "I use Office, no I use OpenOffice, no I use some Office-clone something on Mac" .. UNICODE .. is a standard .. often BADLY implemented !

{kind=link}
{kind=link}
{kind=link}
@vruba That's kind of the thing -- Unicode is *insanely* complicated, even outside of the fact that languages are complicated. For example, the existence of synonymous and homonymous representations was completely avoidable and the mess with bidirectional writing should have been IMO left to a higher layer (though I get why some would disagree with me on this one).

@vruba but isn't it a solved problem by now? Nobody writes new software that's not unicode-aware (and it would be hard to do, because all the systems and languages do it by default now). Converting old software is another matter of course, but that's not specific to Unicode.