
A new paper about cities 🏙️, their structure 🧩 and satellites 🛰️!
"Decoding (urban) form and function using spatially explicit deep learning" by me and @darribas
https://doi.org/10.1016/j.compenvurbsys.2024.102147
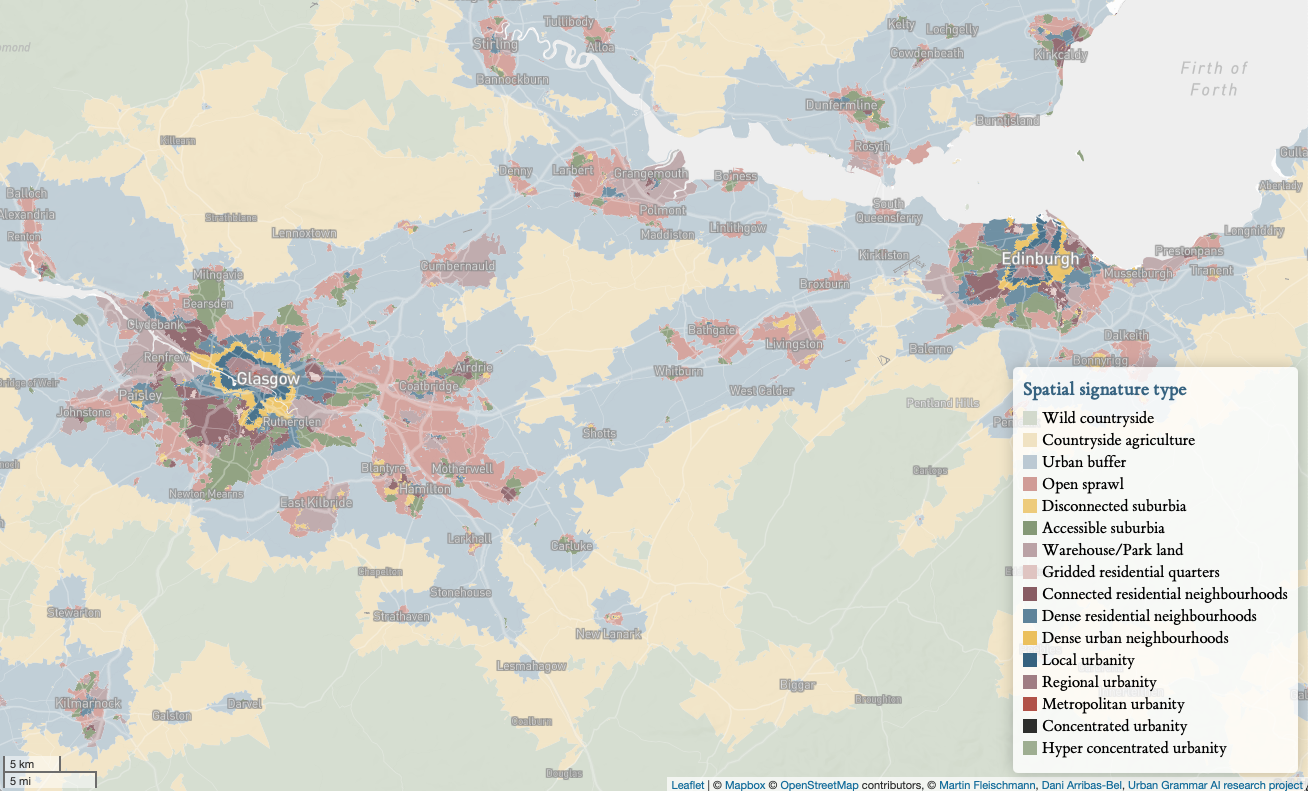
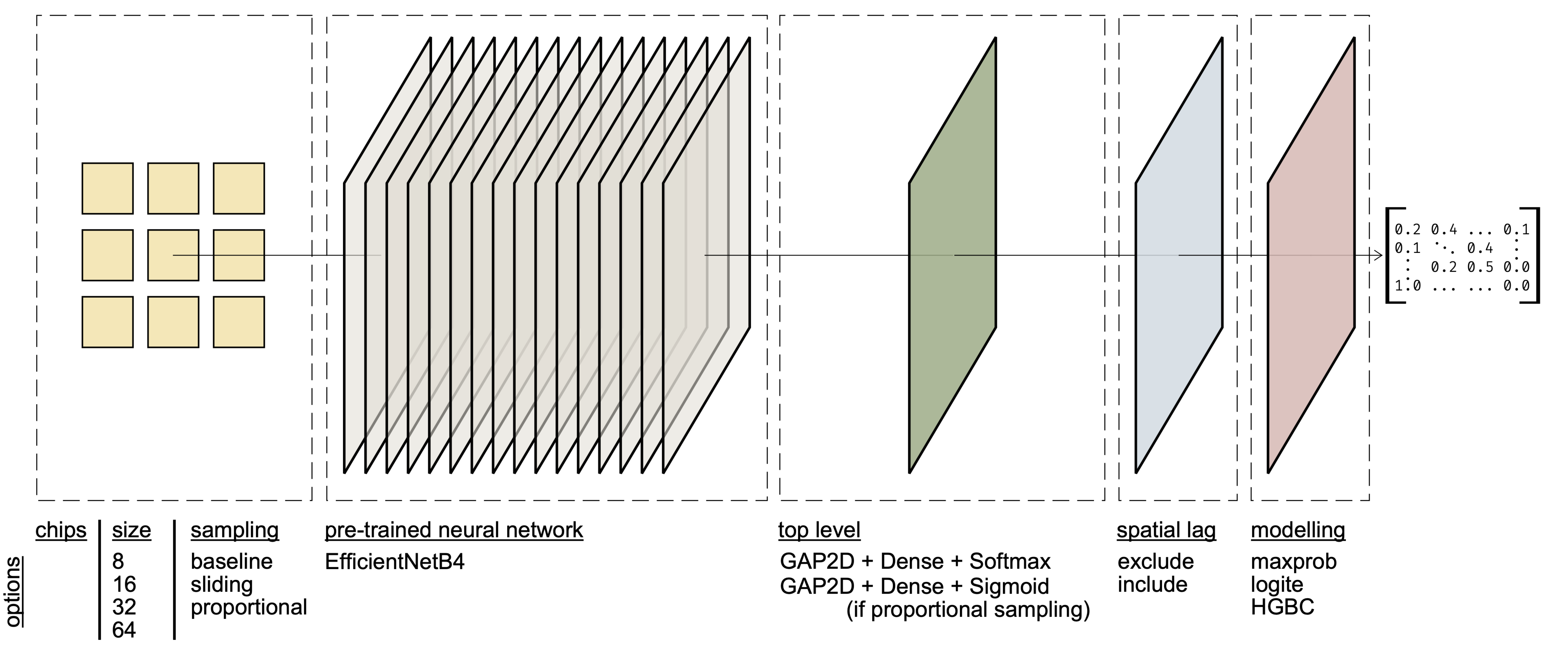
We took spatial signatures and built a neural network to pick them up from Sentinel 2. And since it didn't show great results, we mixed in some geographic data science to learn if and how much it helps.
A quick 🧵 on work that took us 3 years to finish 🙃.
The inclusion of spatial modelling 'on top' of the predictions from the CNN proved to consistently improve the performance of the modelling pipeline, while some other techniques showed occasional success.
In the end, we managed to improve the accuracy of the prediction by almost 0.2 in some cases, bringing the quality of the tricky signature prediction up to the level of common land use or land cover prediction models.
The link to the open access paper is in the first post. The code is available at https://urbangrammarai.xyz/signature_ai/ and the intermediate data at https://doi.org/10.6084/m9.figshare.26203367.


{kind=link}
{kind=link}
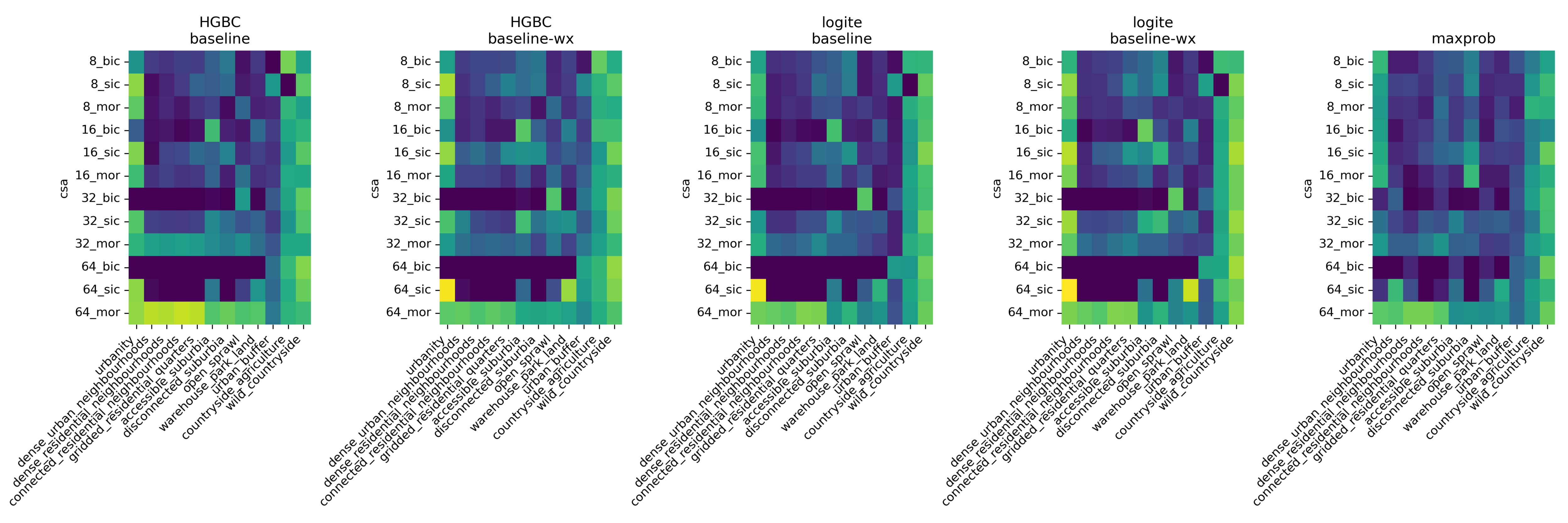{kind=link}
{kind=link}
@djh I think one barrier here is bootstrapping vit training, which as I understand it can be quite tricky at scale – they don’t have the same convexity advantages as CNNs. I’m basing this mostly on https://www.sciencedirect.com/science/article/pii/S003442572300439X (presented well in https://www.youtube.com/watch?v=vacNCxMA_Gw).
@vruba Wait it's not even about transformers.
It's just that I rarely see anyone in the geo space working on remote sensing machine learning projects treating it as a geo task and not simply pretending it's just images.
Examples, like I said: adding positional encoding of time and space:
- e.g. day in the year so we can pick up that snow in winter is reasonable
- e.g. coordinates or at least some sort of quadkey token so we can pick up that snow in winter in Berlin is reasonable
@djh For sure. I share this annoyance. Also:
– Not even trying to understand miltispectral bands.
– Sample-normalizing calibrated, linear data, thereby losing information.
– Augmenting in ways that might make sense for snapshots but do not reflect anything that you would actually see in geospatial data.
– Assuming there is little information in fine details because they’re used to Bayer demosaicked images, where that’s interpolated anyway.

@djh (I am kind of mildly anti-vit, or anti vits being applied everywhere for no particular reason (see ConvNeXt, which I found pretty convincing), but I think the spatiotemporal stuff starts to get into the level of complexity where they might be justified.)