

Charlie Loyd @vruba@everything.happens.horse
- charlie@planet.parts
- work
- geographical pixels
- where
- Xučyun/Oakland, Ohlone land, western Laurentian accretions
- who
- him
You know him on the internet. Eucalypt-adjacent; very occasional writer. Consulting and passively looking for work in geospatial, image processing, and related fields.
Joined Apr 2022
Inspired by @pnorman’s animation, here’s a year of daily OpenStreetMap tile traffic. One frame per UTC day, from the start of September 2022 through end of August 2023. It’s from the public log aggregates, so some low-traffic tiles are left out for (I assume) efficiency and privacy.
{kind=link}
Made a little thing to take fast approximate multivariate medians, at no small cost to my sanity, and it turns out that when I apply it to pixels in California Landscapes time lapse videos (e.g., https://onewilshire.la/@CALandscapeBot/110699293237082262) it’s mostly just Compression Artifact Finder 2023 Pro Edition.
{kind=link}
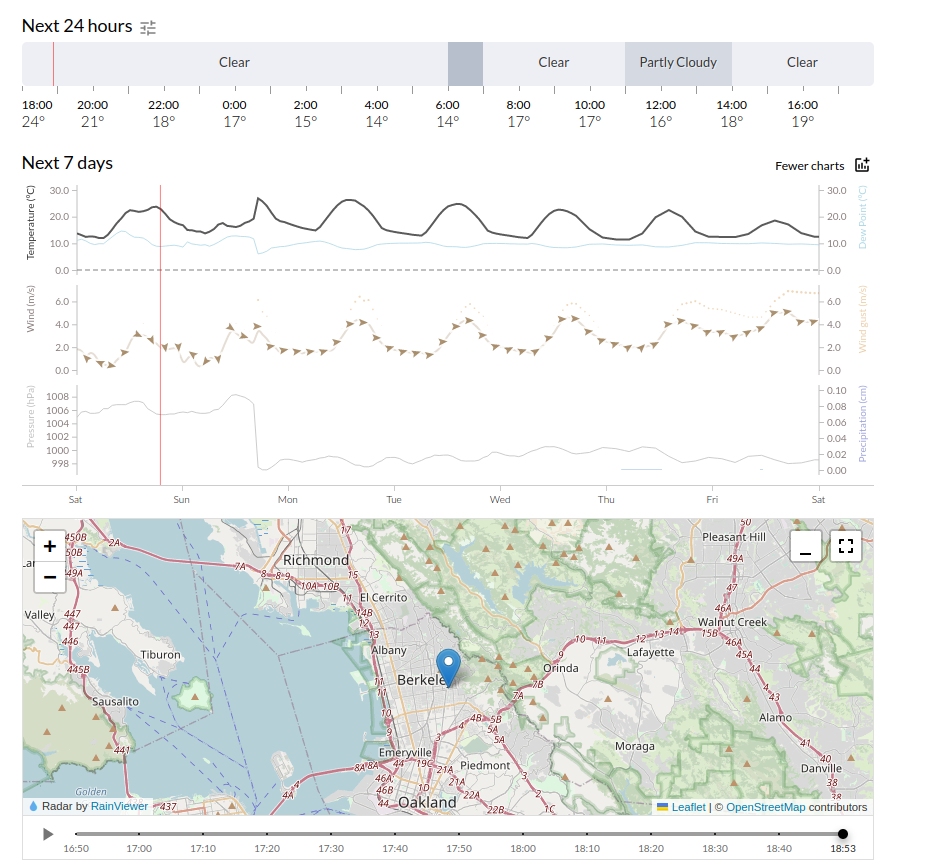
@merrysky Do you consider these discontinuities (on late Tuesday, here) a bug, or a more or less acceptable artifact of merging models?
{kind=link}
OAK, my local airport, wants to expand. I encourage other East Bay people to submit comments: https://www.oaklandairport.com/terminaldevelopment/
Here’s my draft (open to phrasing advice until I send it): https://gist.github.com/celoyd/e0d6fd9cd43d5b18517e8a62cea0f19f
{kind=link}
Avoiding thinking by mapping: an easy, sustainable mental health strategy.
The bit where the guy in charge repeats a factoid this thin as if it’s persuasive and illuminating, because he thinks it’s his vision that matters more than his money, is something that I think most reasonably experienced tech workers would recognize as an even bigger red flag than the parts where he’s like “And now I will use unrated equipment in a safety-of-life application against the strong objections of experts!”
{kind=link}
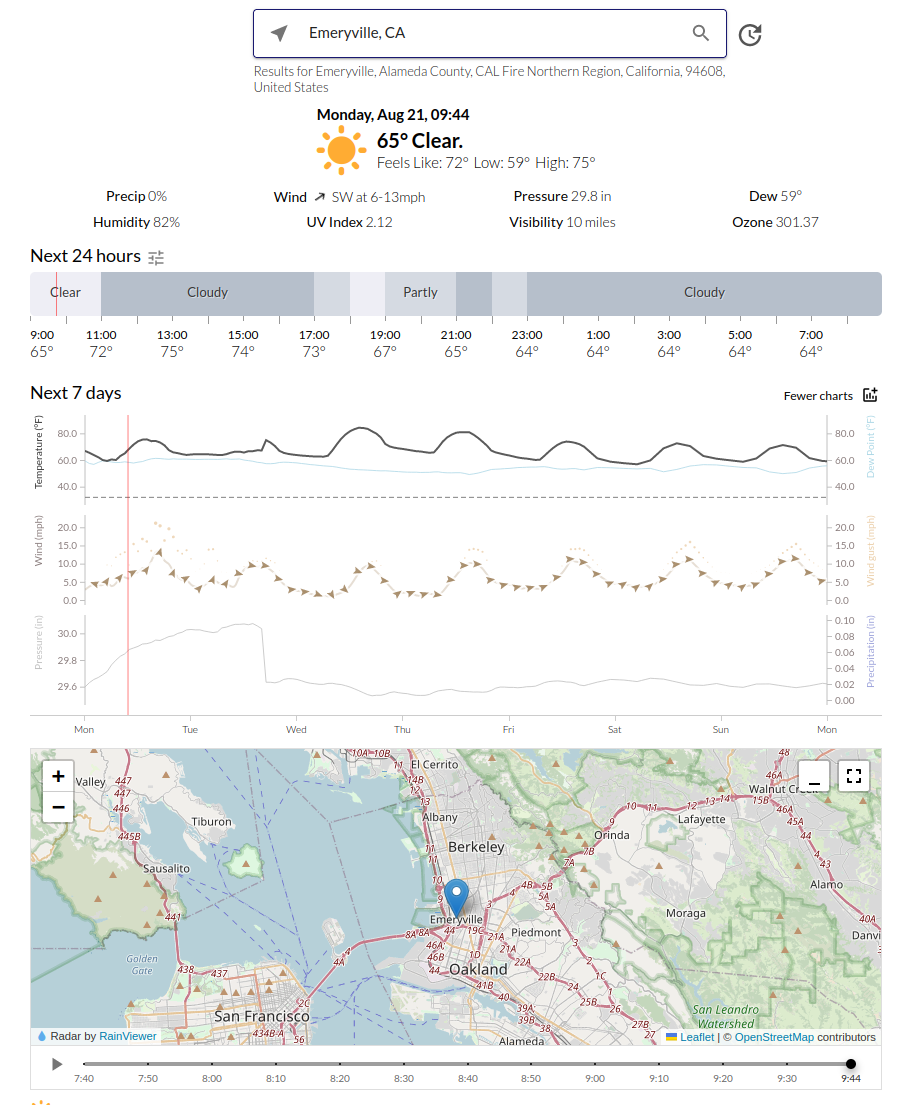
@merrysky Yo, I’m seeing big discontinuities in my forecast (in this case, late on Sunday), presumably from models not matching up. Is this expected?
{kind=link}
ML BS
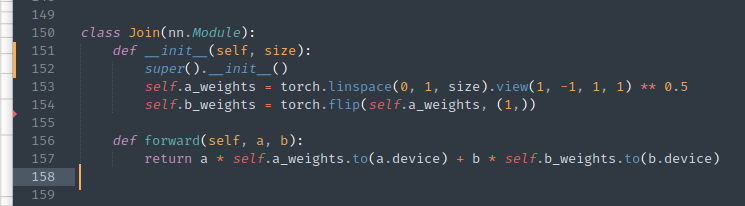
This was a clever idea! Signals should have approximately standard normal distributions, and you mix two Gaussians of the same σ by doing a×sqrt(t) + b×sqrt(1-t) to get output with the same σ at any t. This gives you a nice compromise between concatenation (information-preserving but wasteful) and addition (vice versa). Great!
It didn’t work at all!
{kind=link}
ML BS
Sign up for my course to learn techniques such as SLRBTH (Setting the Learning Rate a Bit Too High)!
{kind=link}
{kind=link}
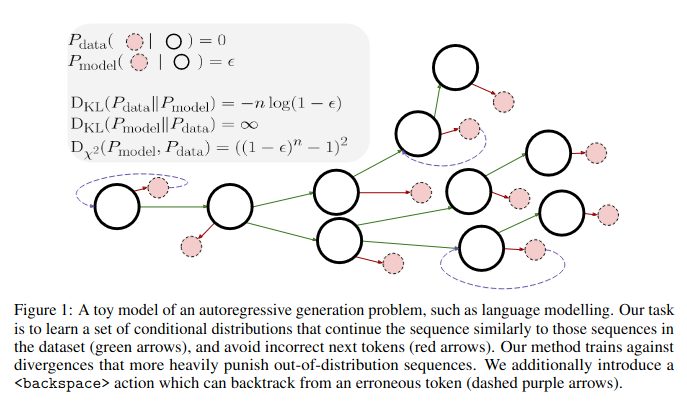
As long as I’m in a listy mood, this language model that backspaces out of dead ends is interesting because:
1. It’s an example of something categorically less interesting than the pro-LLM camp is going to claim, and more interesting than the anti-LLM camp wants to talk about; that gap seems important.
2. It points toward the text diffusion models I keep trying to subtly warn people are probably coming without saying so explicitly, oops, backspace backspace backspace.
{kind=link}
Collaborating on some diffusion model experiments with the cat.
{kind=link}
Back from vacation and attending to important chores such as averaging big stacks of images from webcams to see if they look neat.
{kind=link}
The homebrew GNSS observatory continues to exceed expectations in both signal quality and silliness.
{kind=link}
{kind=link}
ML nonsense
Went back and read the main DDPM paper to check for clues.
And found this spot on page 4 where they specifically say that what I put all that effort into trying is a bad idea.
So that’s neat.
{kind=link}
ML nonsense
This hacky lightweight 4× super-resolver has learned that I want things to look sharp but not too sharp, so it sort of scatters edges around the image like spice in a sauce.
{kind=link}
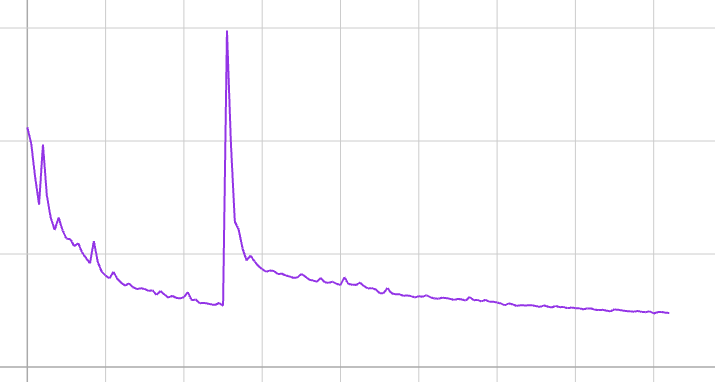
Nodding every time the loss goes down, frowning every time it goes up, pursing my lips and making a note if it’s the same for two batches in a row.
{kind=link}
{kind=link}
- charlie@planet.parts
- work
- geographical pixels
- where
- Xučyun/Oakland, Ohlone land, western Laurentian accretions
- who
- him
You know him on the internet. Eucalypt-adjacent; very occasional writer. Consulting and passively looking for work in geospatial, image processing, and related fields.
Joined Apr 2022
